Data Pipelines & Continuous Data Flow
The Backbone of Edge AI Intelligence
Edge AI is often framed around models, tiny neural networks running on microcontrollers or embedded processors. But in real-world systems, models alone do not create intelligence. Data does. More specifically, continuous, reliable, and well-structured data flow is what transforms Edge AI from a demo into a production-grade system.
Edge AI data management is fundamentally different from cloud-centric approaches because it brings intelligence closer to where data is generated, enabling real-time, deterministic, and reliable decision-making. Unlike the cloud, which depends on connectivity, bandwidth, and latency-tolerant workflows, edge systems must operate continuously under strict timing, power, and safety constraints.
Managing data locally ensures that sensor signals are captured, structured, and transformed into meaningful features without delay or loss, allowing AI models to act instantly and consistently, even in disconnected or harsh environments. It also enhances data privacy, reduces transmission costs, and provides full data lineage from signal to action, which is critical for explainability and regulatory compliance. In essence, while the cloud is ideal for large-scale aggregation and model training, Edge AI data management is what makes intelligent, autonomous, and production-grade systems possible in the real world.
At the edge, where devices operate in real time and often without cloud connectivity, data pipelines are not optional, they are the system itself.
Real-Time Intelligence Requires Continuous Data Flow
Edge devices continuously ingest data from sensors, vibration, current, temperature, pressure, or acoustic signals. This data must move seamlessly through a pipeline:
Sensor → Signal → Feature → Inference → Action
If this flow is interrupted, even briefly, the system loses visibility into the physical world. In applications like motor health monitoring, robotics, or automotive control systems, this can mean:
- Missed anomalies
- Delayed decisions
- Unsafe operating conditions
At the edge, there is no buffer for inconsistency, systems operate in real time, where every missed sample, delayed write, or corrupted signal can directly impact decisions and outcomes. Continuity of data flow is therefore continuity of intelligence: AI models are only as reliable as the steady, structured stream of data they receive.
When data pipelines are deterministic and uninterrupted, signals evolve into trustworthy features, and features drive consistent, actionable inference. But when that flow is broken, intelligence fragments, models lose context, predictions degrade, and systems become unpredictable. In edge environments where timing, safety, and autonomy are critical, maintaining continuous, high-integrity data flow is not just a design goal; it is the foundation that sustains reliable, real-world intelligence.
The Edge Must Replace the Cloud Pipeline
In cloud-based AI, data pipelines are centralized, data is collected, processed, and analyzed remotely. But edge systems operate under very different constraints:
- Limited or intermittent connectivity
- Strict latency requirements
- Safety-critical decision-making
- Privacy and data sovereignty concerns
As a result, the entire pipeline must exist locally on the device: Deterministic data ingestion
- On-device time-series storage
- Real-time feature engineering
- Embedded AI inference
Each edge device effectively becomes a miniature data center, responsible for managing its own intelligence lifecycle from raw data ingestion to final action. Instead of relying on centralized infrastructure, the device must capture high-frequency sensor data, structure and store it reliably, generate features, run AI inference, and preserve results for traceability, all within tight constraints of compute, memory, and power.
This shift demands deterministic data pipelines, power-fail-safe storage, and efficient on-device processing to ensure that intelligence is continuous and trustworthy. By owning the full lifecycle locally, edge devices gain autonomy, reduce dependency on connectivity, and enable real-time, explainable decisions that are essential for production-grade systems.
Continuous Data Enables Learning, Not Just Inference
AI models rely on context. A single data point rarely tells the full story, especially in physical systems where behavior evolves over time.
Continuous data pipelines enable:
- Sliding windows to capture recent behavior
- Lag features to understand trends and progression
- Anomaly detection based on deviation from learned patterns
- Model drift monitoring as conditions change
Without continuous data, AI becomes static, making decisions based on isolated snapshots rather than evolving reality.
True intelligence at the edge emerges from history, not just the present, because meaningful decisions depend on understanding how signals evolve over time rather than reacting to isolated data points. A single measurement rarely tells the full story; it is the patterns, trends, and temporal relationships, captured through stored time-series data, sliding windows, and lag features, that reveal system behavior and early signs of change. By preserving and structuring historical data directly on the device, edge systems gain context, enabling AI models to distinguish between normal variation and developing anomalies. This continuity of memory transforms reactive systems into predictive, explainable ones, where every decision is grounded in both current conditions and learned experience.
Reliability, Safety, and Explainability Depend on Data Continuity
In regulated industries such as automotive, medical devices, and industrial automation, systems must do more than act, they must explain and justify their actions.
Continuous data pipelines provide:
- Data lineage: tracing every decision from sensor input to final action
- Auditability: maintaining records for validation and compliance
- Resilience: recovering safely from power loss or system faults
This enables critical questions to be answered:
- Why did the system detect an anomaly?
- What data led to this decision?
- How has the system behavior changed over time?
Without continuous data, there is no traceability, and without traceability, there is no path to certification or trust. In edge systems operating under safety, regulatory, and operational scrutiny, every decision must be explainable and backed by a clear lineage, from raw sensor input to feature generation, model inference, and final action.
Gaps in data break this chain, making it impossible to validate behavior, reproduce outcomes, or demonstrate compliance with standards. Continuous, structured data ensures that systems can be audited, verified, and improved over time, turning opaque AI decisions into transparent, accountable processes. Ultimately, trust in Edge AI is not built on models alone, but on the integrity and continuity of the data that supports them.
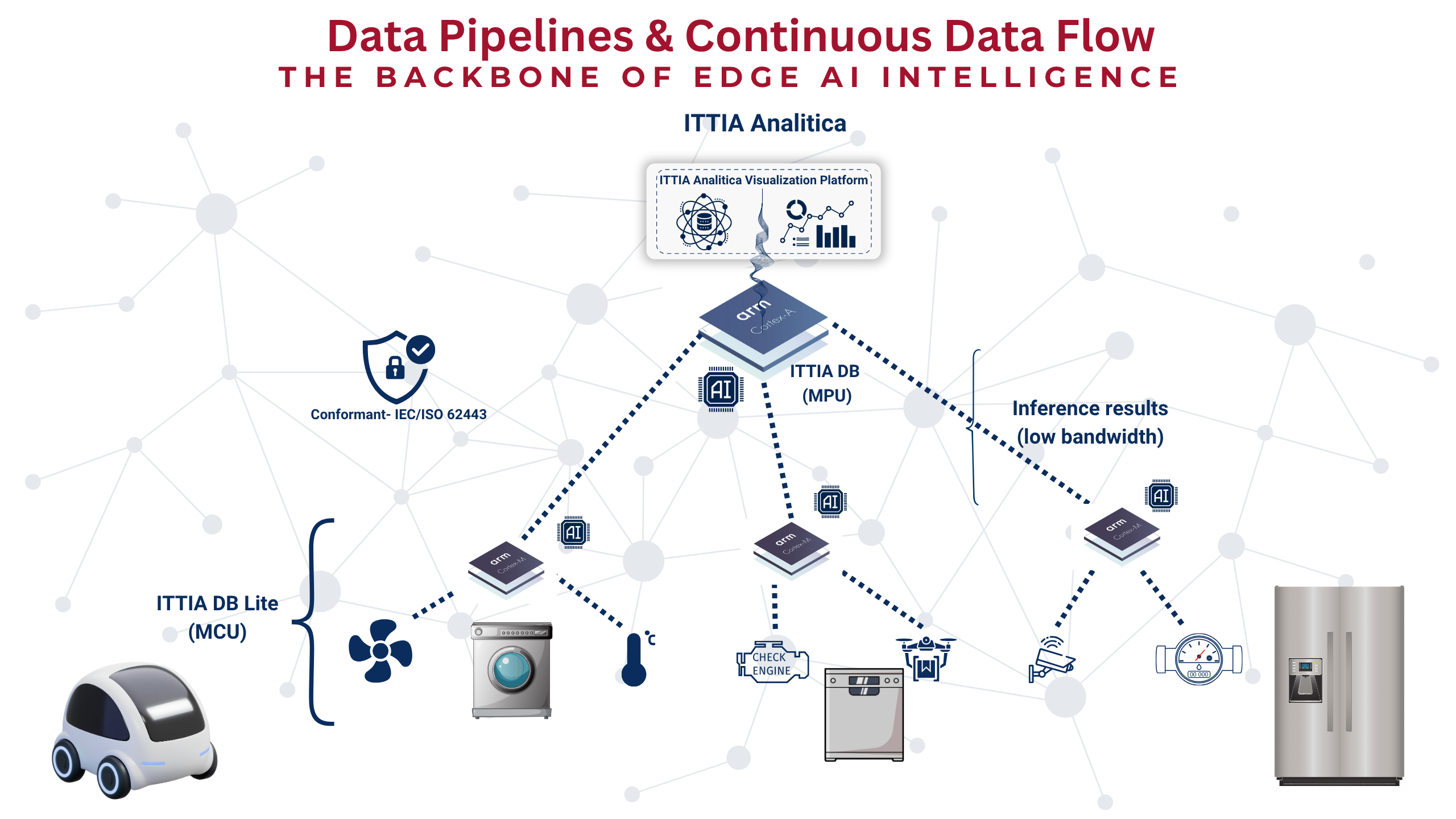
ITTIA DB Platform: Enabling Deterministic Data Pipelines at the Edge
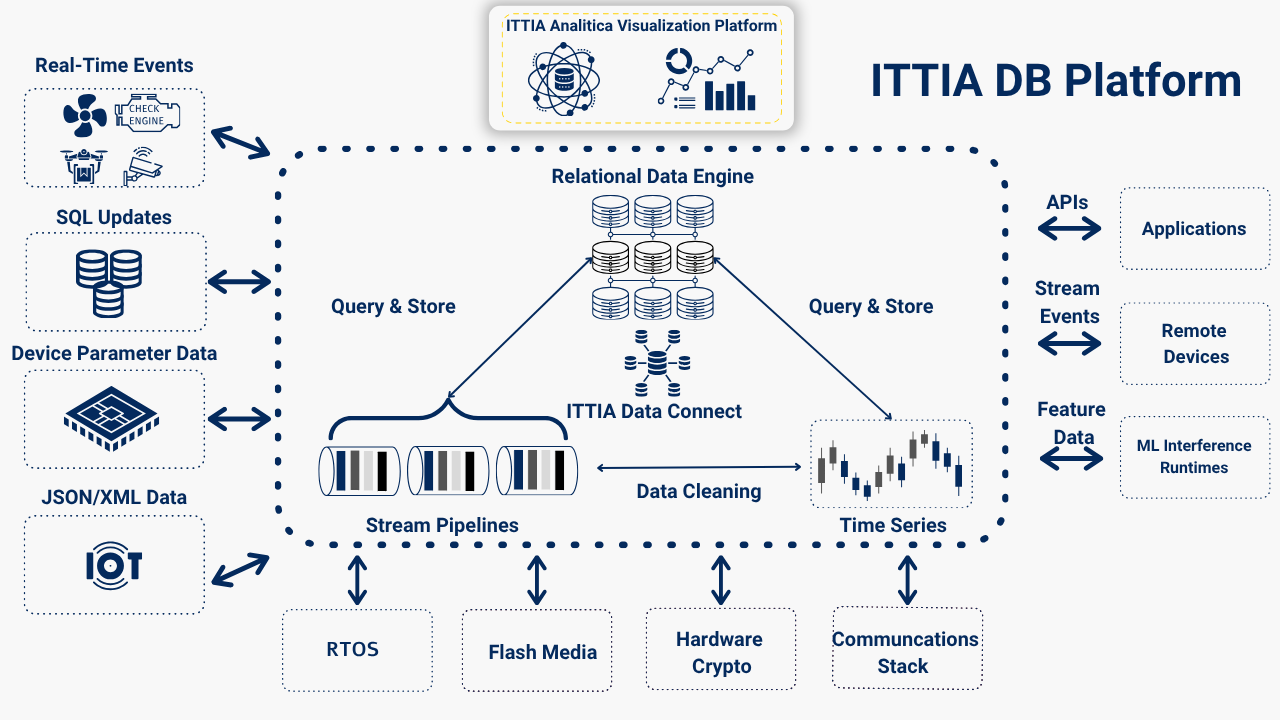
Building a continuous, reliable data pipeline on constrained edge devices is non-trivial. This is where the ITTIA DB Platform delivers a complete, production-ready foundation for Edge AI data computing.
ITTIA DB Lite (for MCUs): Deterministic Data Foundation
On microcontrollers, resources are limited and timing is critical. ITTIA DB Lite provides:
- Deterministic, low-latency data ingestion and storage
- Time-series optimization for high-frequency sensor data
- Sliding windows, lag features, and in-place data preparation
- Power-fail-safe persistence with bounded resource usage
This ensures that even the smallest devices can maintain continuous, reliable data flow without disrupting control loops.
ITTIA DB (for MPUs): Scalable Edge Data Management
On more capable processors (MPUs), ITTIA DB extends the pipeline:
- High-performance storage for large datasets
- Concurrent access for multi-threaded AI and application workloads
- Advanced querying and structured data management
- Integration with Linux, QNX, and RTOS environments
This allows edge gateways, domain controllers, and embedded systems to scale data pipelines while maintaining determinism.
ITTIA Analitica: Insight, Monitoring, and Explainability
Data pipelines are only valuable if they produce actionable insights. ITTIA Analitica provides:
- On-device visualization of time-series data and health metrics
- Real-time dashboards for anomaly detection and system behavior
- Explainability through data lineage and feature tracking
- Monitoring of AI outputs and system performance
This transforms raw data into operational intelligence and transparency.
ITTIA Data Connect: Controlled Data Distribution
Edge systems rarely operate in isolation. ITTIA Data Connect enables:
- Reliable, selective data synchronization between MCU ↔ MPU ↔ gateway
- Bandwidth-efficient data transfer (only what matters)
- Fleet-level aggregation and remote diagnostics
- Seamless integration with cloud or enterprise systems when needed
- This ensures that continuous data flow extends beyond the device, without compromising autonomy.
From Prototype to Production: The Role of Data Pipelines
Many Edge AI demonstrations focus on model accuracy using pre-collected datasets. These prototypes often overlook:
- Persistent data storage
- Deterministic execution
- Continuous feature generation
- Fault tolerance and recovery
In production, these are not optional, they are mandatory.
With the ITTIA DB Platform:
- Data is consistently captured under all conditions
- Features are generated reliably and deterministically
- AI models operate on high-quality, structured inputs
- Systems behave predictably under stress
This is the difference between a proof-of-concept and a deployable system.
Conclusion: Edge AI is a Data Problem First
Edge AI success is not defined by the sophistication of the model, but by the quality, continuity, and reliability of the data pipeline feeding it. Data pipelines and continuous data flow at the edge are:
- The foundation of real-time intelligence
- The replacement for cloud infrastructure
- The enabler of learning and adaptation
- The backbone of safety, reliability, and explainability
With the ITTIA DB Platform, including ITTIA DB Lite, ITTIA DB, ITTIA Analitica, and ITTIA Data Connect, developers gain a complete, deterministic, and production-ready data infrastructure for Edge AI.
Final Thoughts
AI models alone don’t create intelligent systems, data does. At the edge, where decisions must be immediate, reliable, and explainable, intelligence is only as strong as the data pipeline that sustains it. Without deterministic ingestion, continuous data flow, structured storage, and real-time feature generation, even the most advanced models degrade into fragile components. This is where the ITTIA DB Platform delivers critical value: with ITTIA DB Lite for MCUs and ITTIA DB for MPUs providing power-fail-safe, deterministic data management; ITTIA Analitica enabling on-device visibility, monitoring, and explainability; and ITTIA Data Connect ensuring selective, reliable data movement beyond the device.
Together, they form a complete edge data infrastructure that transforms raw signals into trustworthy intelligence, making Edge AI systems not just functional, but production-ready, auditable, and resilient.
